
As engineers we are very used to manipulating data in well-know structures like arrays, queues, sets and maps as they solve day-to-day issues - like when you need to manipulate relationships from database on the client-side, you use Sets/Maps to prevent O(nˆ2)searches.
But one of the not-so common data structures is the Bitmap - being very math-focused and tailored for certain scenarios - it's usually forgotten.
Today we are going to showcase one scenario where it might be interesting to use it.
The Problem with Access Control
In many SaaS platforms - the ACL model usually revolves around many-to-many relationships, as example - imagine you have a software that solves for real-time communication such as Slack but give it a bit more of spiciness (as if Slack needs it?) - give it 1 more layer of control.
You would have an User U that belongs to Groups G. And each Group has it's own set of Teams T. Each sent message for a Team T should be Broadcasted to all online Users that have access to Team T.
With this - you do have a problem where you need to ensure that messages CANNOT be routed to wrong recipients and other Teams may join the same conversation.
The Challenge Is About Scale
You can scale this by simply doing database queries - up to a certain scale this is fairly simple. A query would hardly reach >50ms if well-indexed. Even if it was poorly optimized wouldn't be a huge problem. Nonetheless, maybe even the amount of notifications is not a problem!
But We Like To Pretend Windmills are Dragons
The real challenge is:
What if, either lucky or the biggest salesman ever, your company reaches a huge milestone and now scale hits upon the backdoor
The Scenario:
Out of a sudden now you are handling 30K+ notifications per second. Your engineering team, knowing the domain of the product, designed almost all modeling and infrastructure with this in mind. But yet hammering the database 30K+ times per second is far from ideal - although injecting$$$ solves it - we like to pretend people care for green solutions in this blog.
At a certain day - a Slack thread arrives:
Engineer 1: Since the last Go-live our database system is just crawling man... I don't know how long we can sustain this.
Engineer 2: Yeah... We jumped from 10K Messages/Sec to more than 30K - no wonder it just got hammered
Engineer 1: I think it's time to optimize this but that might be hard - maybe some caching layer?
Engineer 2: Yeah, caching could be the way - but how?
Engineer 1: I have no idea to be honest. it might be too much data for Redis?
Engineer 3: Yo I am pretty sure some has solved this...
CTO: I think we can use Bitmaps for that ?
BitMaps and Access Control
Finally we reached the main part of this article - Bitmaps - are data structures specialized in binary operations - being fast and space-efficient. By such they efficiently tell us wether something is ON/OFF or TRUE/FALSE.
The Design
Each Tenant would have all of its Teams lay'ed out in Redis Bitmaps such as:
teams:<tenantId>:<tid>
online-users:<tenantId>
(Assuming you have de-normalized this relations due to it's read-pattern) Instead of doing:
SELECT
ug.user
FROM
groups ug
WHERE
ug.teams IN (<list of teams>)
AND ug.tenantId = <tenantId>
You would simply use a small LuaScript:
local tenantId = ARGV[1]
local tmp_or_key = 'tmp:teams'
local notify_key = 'tmp:notification'
local online_key = 'online-users:' + tenantId
-- Store tmp key for all SET bitmaps using OR operator
redis.call('BITOP', 'OR', tmp_or_key, unpack(KEYS))
-- Store the key with the
redis.call('BITOP', 'AND', notify_key, tmp_or_key, online_key)
-- Extract those Ids
local max_index = redis.call('STRLEN', notify_key) * 8
local notified_users = {}
for i = 0, max_index - 1 do
local bit = redis.call('GETBIT', notify_key, i)
if bit == 1 then
table.insert(notified_users, i)
end
end
-- Optional
redis.call('DEL', tmp_or_key)
return notified_users
The Outcome
So revisiting what changed in the infrastructure:
Before, you were doing 30K database operations - which include all the way from Parsing, Planning, Optimizing, Checking Buffer Cache - maybe reading from Disk. It's even worse, if your database is write-specialized like those with LSM Storage Engines.
Instead of doing all of this: You are now flipping bits in a pretty-much efficient CPU cache.
The current scenario?
- Your database is free of abusive reads.
- It can focus on the write-heavy nature of Chat systems
- Notifications are now even faster - what took (luckily) under 50ms is now under 1ms
- Downgrade that database man and save some money!
Take Aways Points Notes
- You might be asking yourself if you couldn't do so with normal
Sets. And the answer is:Yes. The trade-offs?RAM Storage($$$), CPU Performance and Latency overall - You could easily fit more than 10 Million Users within less than 5GB of data using Roaring Bitmaps!
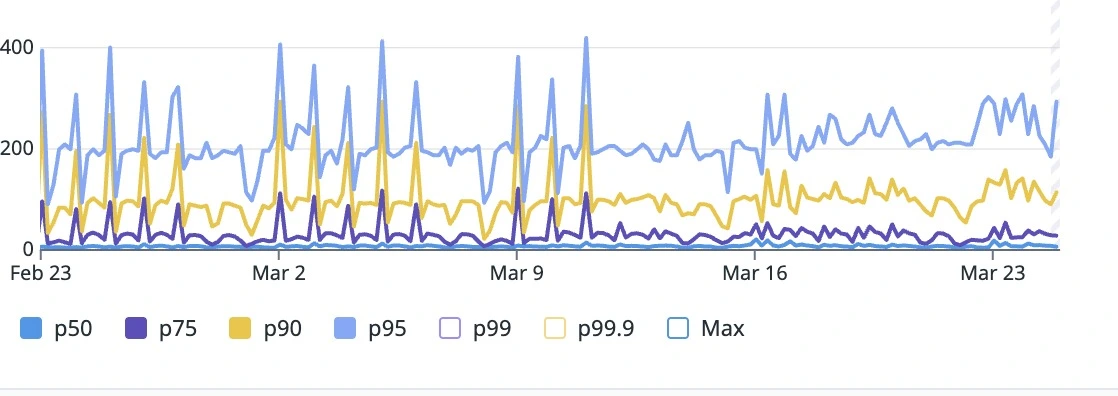
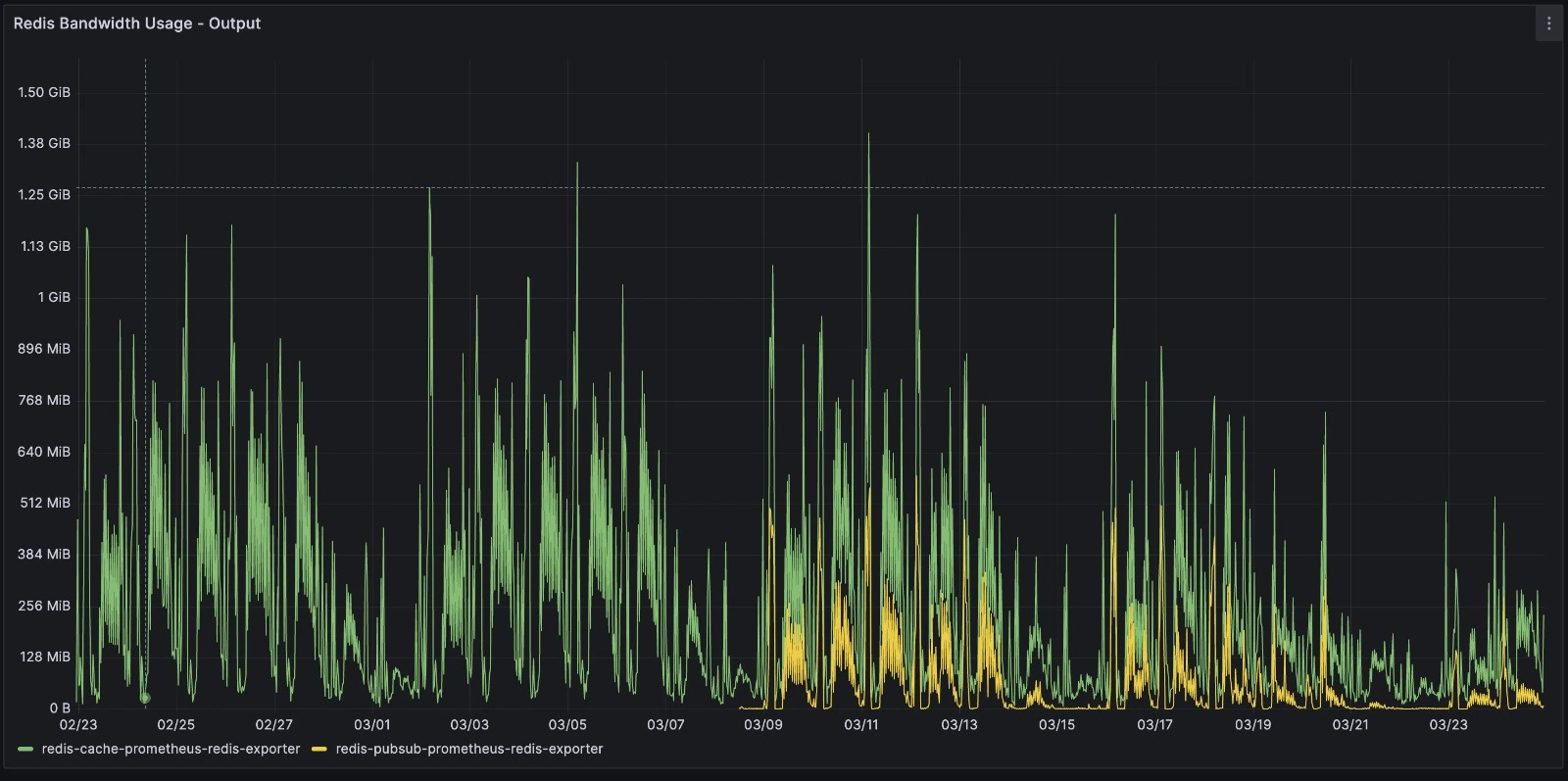
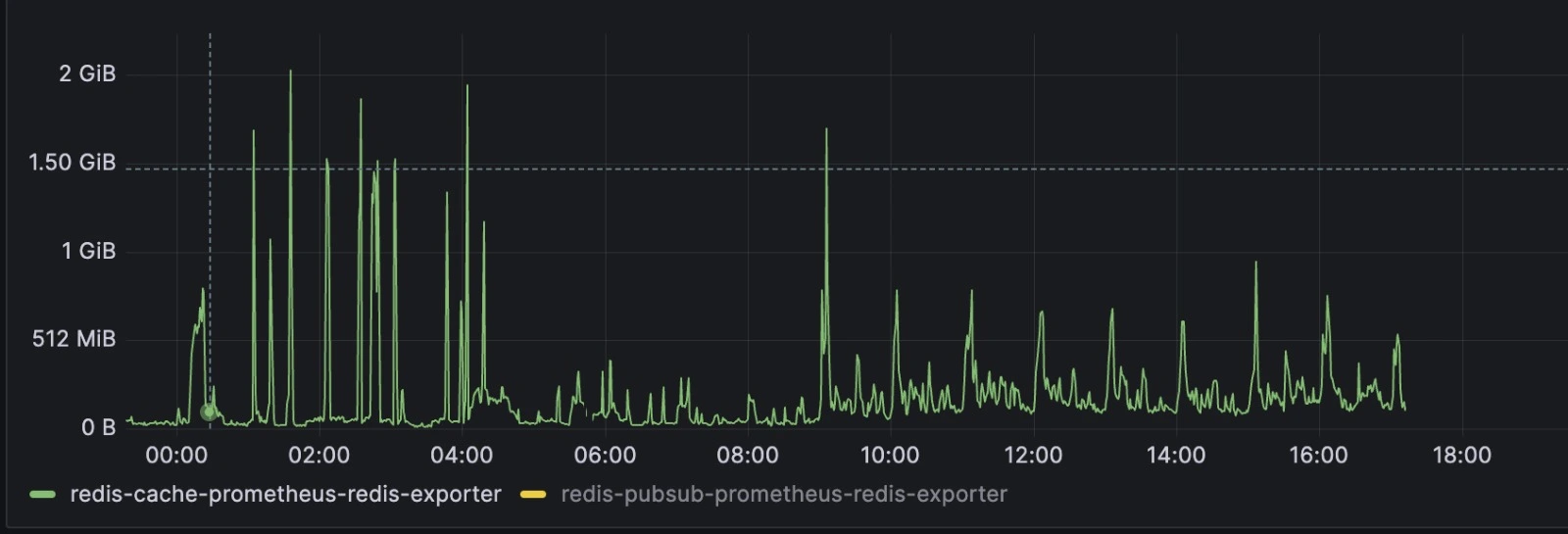 Pre-Rollout Monday (Busiest day of week)
Pre-Rollout Monday (Busiest day of week)
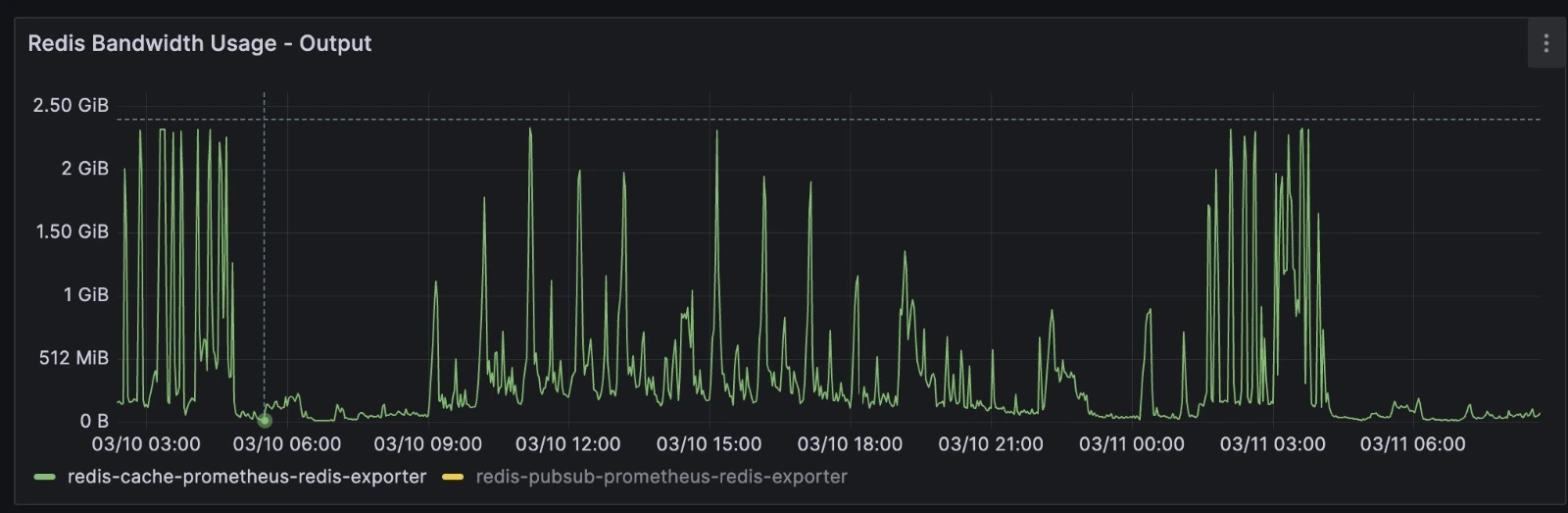







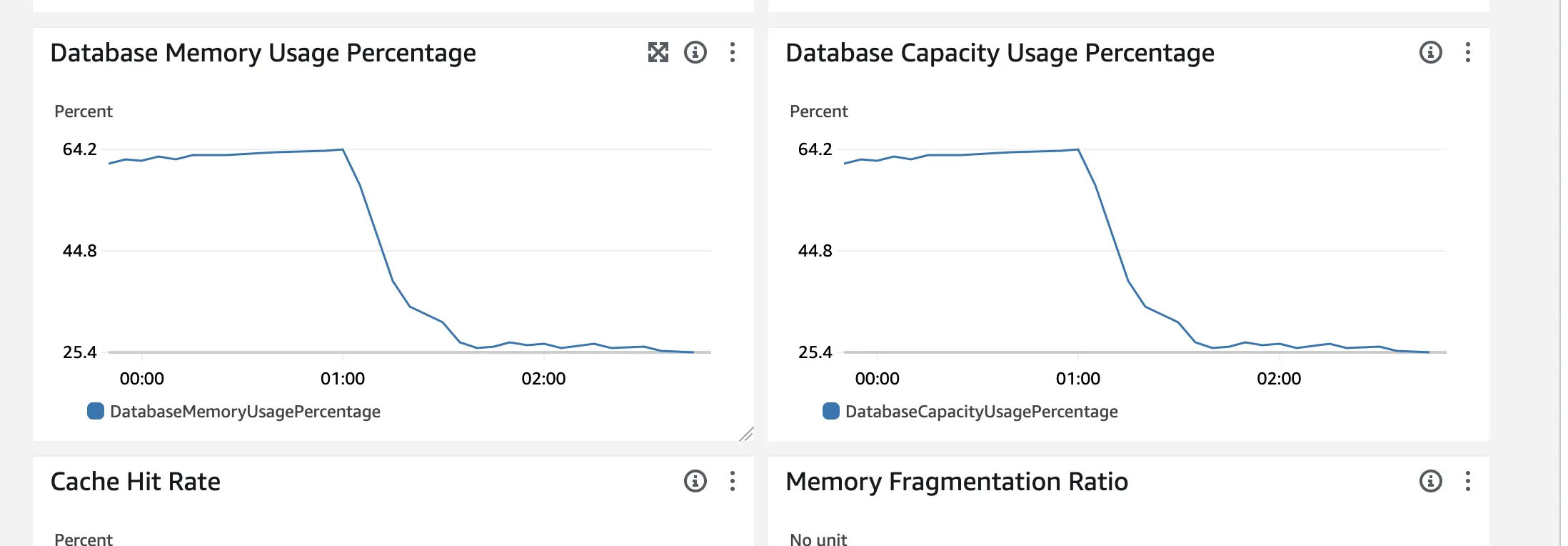
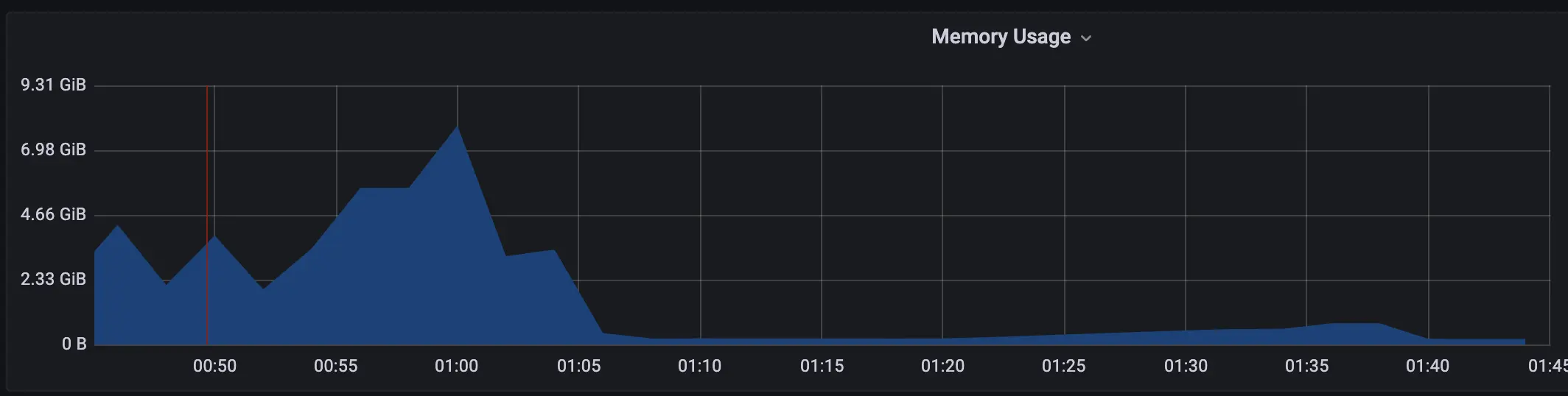 We are now - trying to be play safe and still oversize - safely allocating 1/4 of the resources. The git diff was our first resource dump - we went even further.
We are now - trying to be play safe and still oversize - safely allocating 1/4 of the resources. The git diff was our first resource dump - we went even further.