
My current company - Luma Health Inc - has an Event-Driven Architecture where all of our backend systems interact via async messaging/jobs. Thus our backbone is sustained by an AMQP broker - RabbitMQ - which routes the jobs to interested services.
Since our jobs are very critical - we cannot support failures AND should design to make the system more resilient because well..we don't want a patient not being notified of their appointment, appointments not being created when they should, patients showing off into facilities where they were never notified the patient had something scheduled.
Besides the infra and product reliability - some use cases could need postponing - maybe reaching out to an external system who's offline/or not responding. Maybe some error which needs a retry - who knows?
The fact is, delaying/retry is a very frequent requirement into Event Driven Architectures. With this a service responsible for doing it was created - and it worked fine.
But - as the company sold bigger contracts and grew up in scale - this system was almost stressed out and not reliable.
The Unreliable Design
Before giving the symptoms, let's talk about the organism itself - the service old design.
The design was really straightforward - if our service handlers asked for a postpone OR we failed to send the message to RabbitMQ - we just insert the JSON object from the Job into a Redis Sorted Set and using the Score as the timestamp which it was meant to be retried/published again.
To publish back into RabbitMQ the postponed messages, a job would be triggered each 5 seconds - doing the following:
- Read from a
setkey containing all the existingsorted setkeys - basically the queue name - Fetch jobs using
zrangebyscorefrom 0 to current timestamp BUTlimitto 5K jobs. - Publish the job to RabbitMQ and remove it from
sorted set
The Issues
This solution actually scaled up until 1-2 years ago when we started having issues with it - the main one's being:
- It could not catch up to a huge backlog of delayed messages
- It would eventually OOM or SPIKE up to 40GB of memory
- Due to things being fetched into memory AND some instability OR even some internal logic - we could end up shoveling too much data into Redis - the service just died 💀
- We could not scale horizontally - due to consuming and fetching objects into memory before deleting them.
The Solution
The solution was very simple: we implemented something that I liked to call streaming approach
Using the same data structure, we are now:
- Running a
zcountfrom 0 to current timestamp- Counting the amount of Jobs -> returning N
- Creating an
Async Iteratorfor N times - that used thezpopminmethod from Rediszpopminbasically returns AND removes the least score object - ie most recent timestamp
The processor for the SortedSet

The Async Iterator
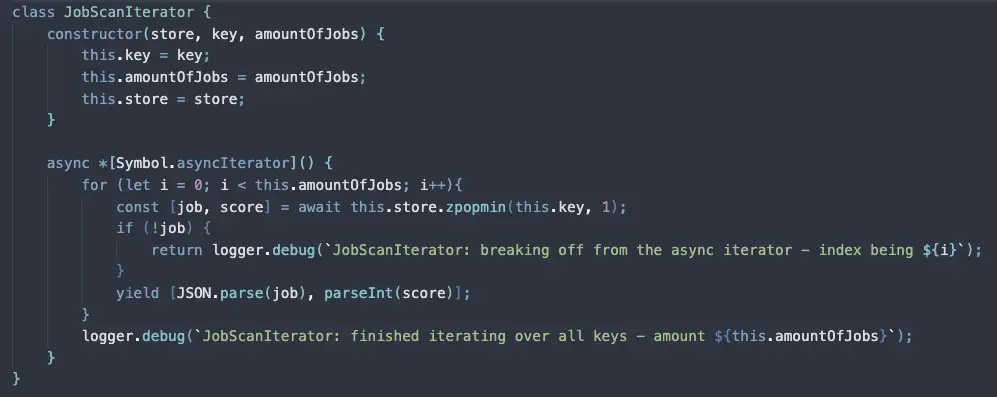
And that's all!
This simple algorithm change annihilated the need for:
- Big In Memory fetches - makes our memory allocation big
- Limit of 5K in fetches - makes our throughput lower
Results - which I think the screenshots can speak for themselves
We processed the entire backlog of 40GB of pending jobs pretty quickly
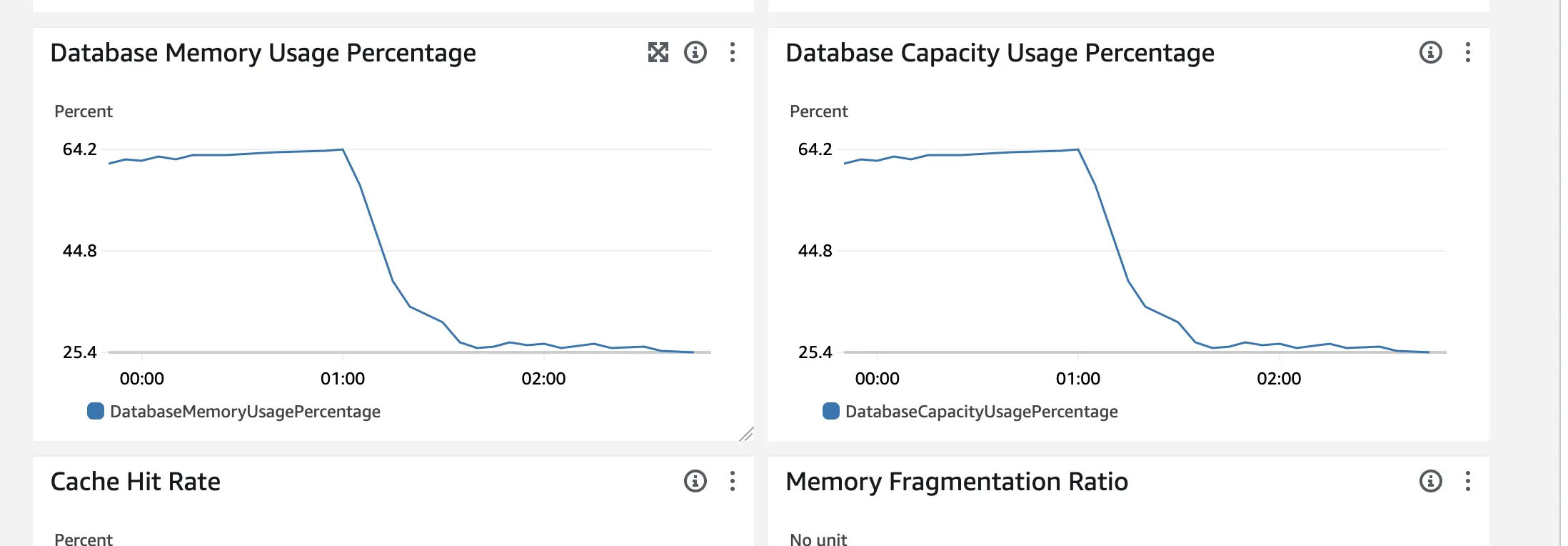
From a constant usage of ~8GB - we dropped down to ~200MB
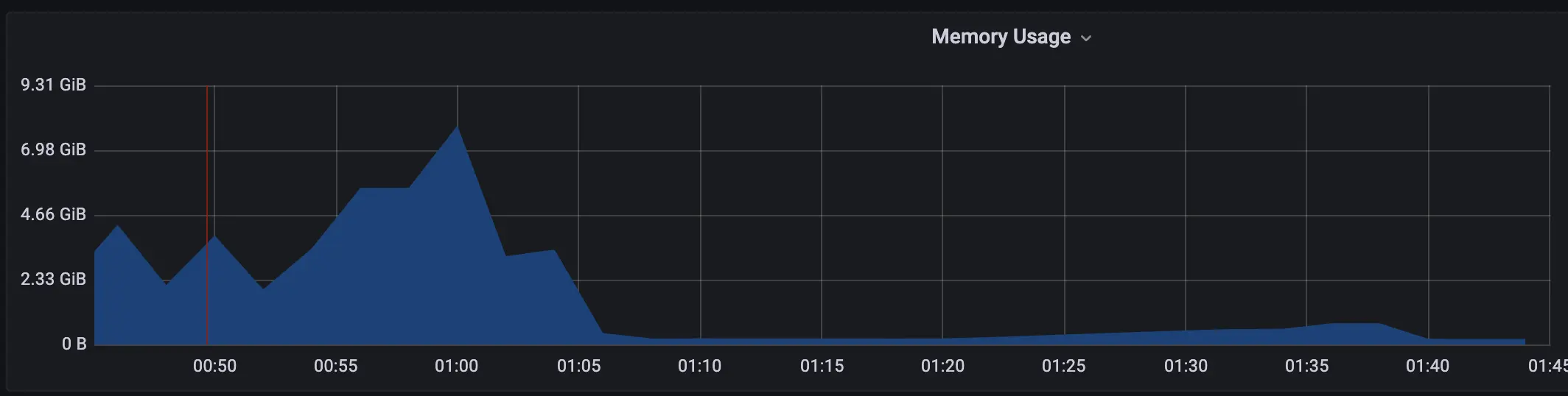 We are now - trying to be play safe and still oversize - safely allocating 1/4 of the resources. The git diff was our first resource dump - we went even further.
We are now - trying to be play safe and still oversize - safely allocating 1/4 of the resources. The git diff was our first resource dump - we went even further.

Money-wise: We are talking at least of 1K USD/month AND more in the future if we can lower our ElastiCache instance.
Take Away Points
- Redis is a Distributed DataStructure database - more than just a simply KeyValue pair storage.
- You can achieve great designs using Redis
- Be careful because the way you design a solution with Redis may be costly in the future
Final Thoughts
There could be a lot of discussion wether this is a great way of doing jobs postponing, if Redis is the right storage, if we should really postpone jobs for small network hiccups, shouldn't we leverage DelayedExchange from Rabbit? - etc... But at the end of the day - to succeed as a company we need to solve problems in our daily routine. Some problems are worth, some are not. It's always - one step at a time.