Some weeks ago, we had a incident that was caused mainly due to how we delay job execution. One queue had abnormal behavior during the weekends, which our monitoring systems caught, but we were expecting system to be self-healing and be able to kick through this small hiccup. Tuesday we noticed something was off with our integration systems - where a code that was running for more than a year stopped working at the same time we rolled it for a new big customer.
I got involved early in the incident due to how often I touch that component of the backend and we initiated investigation so we could get back to the customer as fast as possible with some good news.
After some hours of investigation we ended up concluding that our long polling mechanism had a hot-loop on a certain queue - which in turn was always retrying delays. The first time this edge case was triggered happened during the weekends where we saw the previous abnormal behavior. Due to always re-delaying jobs, the amount of postponed jobs to this queue would never actually drain and thus this component would eternally get stuck while trying to drain postponed jobs - delaying all the other queues from the platform.
In a quick 1/2 hour solution we shipped code to stop retrying jobs after more than N retries and unblocking the hot loop.
What about the future?
All that to say what? What is has to do with Redis?
As described the previous post from this series - the job delaying mechanism lives within Redis where we use a Sorted Set to pull the next job. We fanout to a certain amount in parallel - but we only restart this processing after all possible queue targets were drained up until some upper bound timestamp (being the score in a SortedSet).
With this fragility in mind and the upcoming code-freeze of December - I suggested to rewrite this design completely.
Current Design
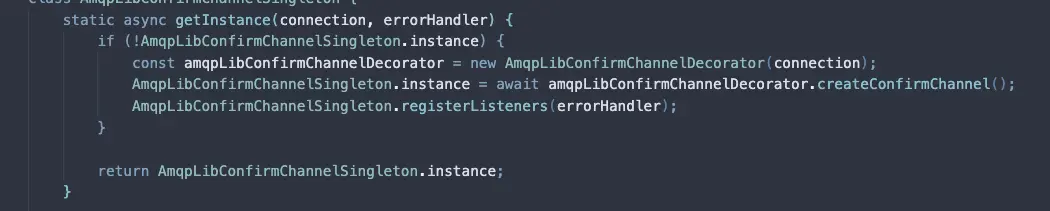
Whenever a service requests an postpone - which can be either intentionally - calling the method to postpone it OR unintentionally - due to some IO failure, protocol error or some ephemeral channel churn - the job flows through this DelayedJobsStorage design.
The current production design is a simple Sorted Set from Redis where timestamps are the score and key being the job serialized into string.
On the infrastructure side, we use a cache.r7g.12xlarge ElastiCache (~300GB 🚨) instance to sustain our load SPIKES - like some instabilities or big customers data.
In the other end, there's a separate backend component Scheduler that is responsible for triggering individual jobs at certain interval. This component triggers a service that runs a long-polling logic until the current timestamp.


New Design
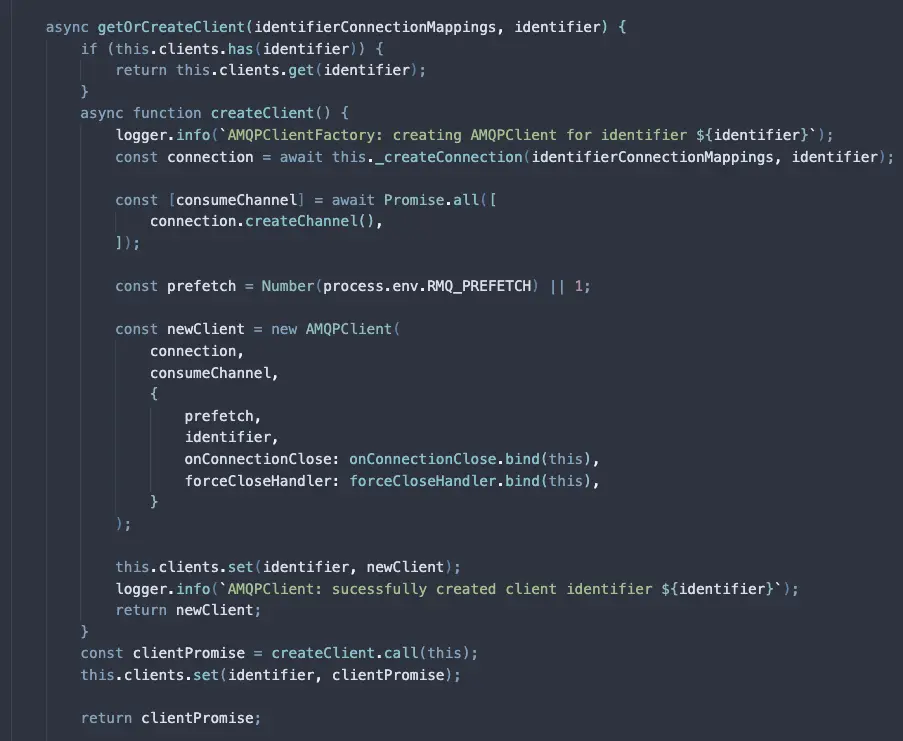
I've created some abstractions to make it easier to implement new storage backends like S3, VFS and many more.
Redis is now running as a mainly as reference-to-data component and only stores entire jobs if they are within the next ~2 seconds or some failure happens.
The storage rationale happens with a couple considerations:
- How long are we planning to postpone?
- How big (byte size) is this job?
- Is this storage backend rolled out for certain queue OR tenant _id?
- Is this storage available? If not, fall back to Redis
We also changed the core logic behind the backend service that re-enqueues delayed jobs:
- Removed the coupling with Scheduler:
- Instead of waiting for some schedule job trigger the backend service, it triggers itself given a certain interval.
- Circuit Breaking:
- Jobs keeps being re-enqueued up to a certain timeout. Preventing one cycle of starving resources OR locking entire service in some hot-loop.
- Concurrent Processing with Semaphores:
- We would always have up to N concurrent processing target queues - decoupled from other executions.
- Speeds up draining time.
- Better visibility:
- We implemented proper monitoring such as latencies for each re-enqueue, amount of re-enqueues and failure/successful re-enqueues.
- *Horizontally Scale by Controlling the ZPOPMIN:
- Pop the least score up to an upper-bound timestamp.
- This enables us to have multiple instances running which we were unable in the past due to the Singleton Design we had.




Example
Lets use for example - storing a job for 10minutes that has a medium size due to the context it needs to carry. We would store the job data into S3 then insert a key into Redis formatted as s3::some-queue::384192393192::<some-generated-uui>
When trying to re-enqueue the job - the abstraction easily understands the protocol as being s3. This abstraction then uses the implementation of s3 which knows where to fetch a certain job by this uuid.
What to expect from this Design
- Infrastructure downsizing: From
300GBto>10GB- Currently we have
4millionof keys stored consuming up to200GBof RAM - In the new design this would be
~64mb- if we calculateuuidbeing 128bits and omit the other small appended data. - Roughly we are expecting to downsize to
10GB- since brief postpones can still occurs and overload it. Experimentation will lead us to decide the proper size.
- Currently we have
- Independency: Decouple backend components preventing service A stopping service B of working properly
- Speed: N replicas will consume queues much faster in some abnormal load
- Horizontal Scalability/Reliability: Multiple Consuming replicas.
- Tail-Latency Aware: Latency-Sensitive components will be decoupled such as WebSocket notifications, Chat Messages and all real time communication - heavily used in the platform
Concerns
- RPS - How many jobs are being delayed per sec and their latencies? p75, p90, p99
- S3 speed for large objects -> Will it impact our re-enqueueing speed?
- Proper Redis sizing -> How far can we push lower?
- Redis is still a single point of failure -> What if Redis just dies?