
Back in 2022 @Luma had a major outage which caused hours of downtime, angry customers and lots of engineering efforts to return the product back to normal.
One of the discoveries made at that time was a hard truth: we modeled our internal IAM object poorly.
inb4: PHI
On the HealthCare Tech Industry - and outside of it - Patient Health Information (PHI) is of major importance. When applied to Luma's platform - being very brief - states that patient's data should belong only to facilities that they had interaction with/allowed them to have. This is to protect patient's health information and access to their data. It's a US-government enforced law.
IAM Model
Our IAM model is something called session object - a pretty simple concept - it concentrates the user's token, settings, groups, facilities and more metadata about itself. We use this session throughout all backend components of Luma to properly apply this PHI filtering rule.
One of the bad decision back then was to simply pull all facilities and groups inside a JSON object and cache it. But then you would probably ask...
What's the problem of it?
When Luma grown it's scale - we started onboarding bigger and bigger customers - with their own setup of account leading to N different use-cases.
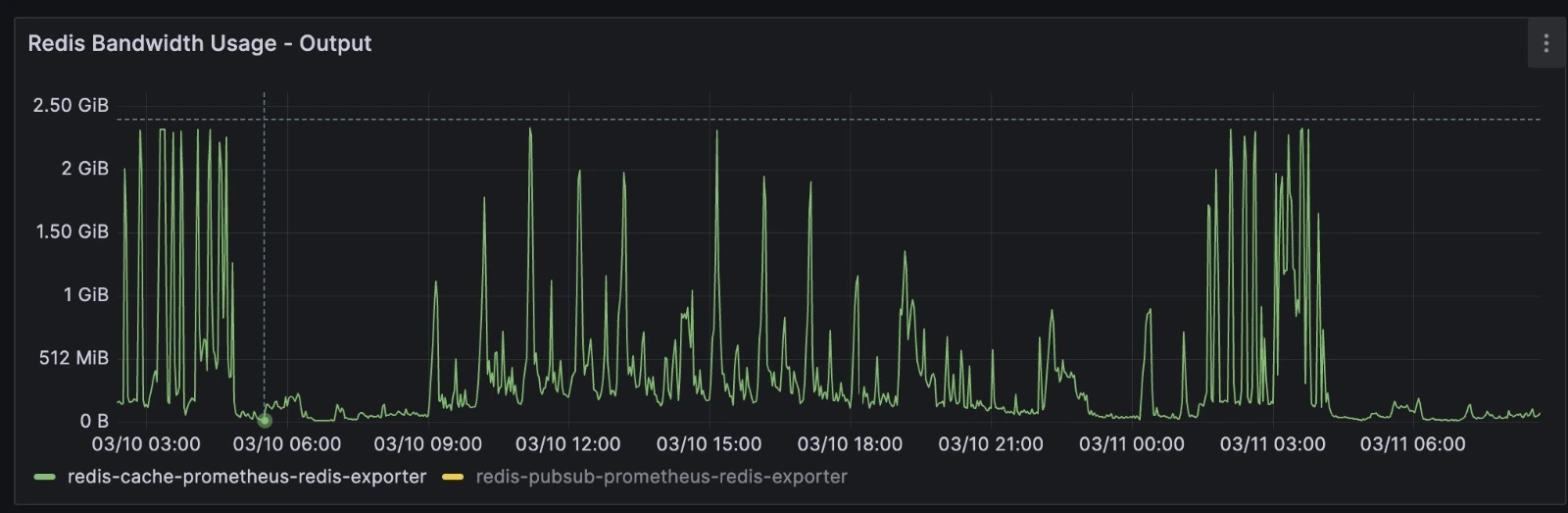
Summing up some very creative account setups and huge customers - we ended up creating something unexpected - session object storing up to 2.6MB of pure JSON text.
And yes, you did read it right - an entire PDF!!
Now imagine that for each job, we actually pulled cached sessions up to 100x - or even more. Luma produces average of 2K jobs per second spiking up to 10K
That's ALOT of Network usage. - easily surpassing 2GB per second - aka more than 15Gbps.
For reference - cache.m6g.8xlarge which is a fair-sized cache instance has this bandwidth.
Infrastructure Impact
All of a sudden Luma has this scenario:
- Slow and unstable HTTP APIs
- Had to oversize more than usual to handle same load - a very low overall ~400RPS
- Had to split our Broker instance into smaller and focused one's
- Had to increase our cache size
- We had to create one thing called
pubsub-service(yes and yes, no bueno) to offload services of slow publishes. - With this - we also created a
joblessfeature which forced backend components to publish only thejobIdand route the job content itself via Redis.
The Business Impact? Money being thrown away and unsatisfied customers
Given it's mission-critical importance of Session - the risks were just too high until 1st of March 2025.
After good months of investigation, searching code, trying to run AST analysis (codemod) in almost the entire codebase and libraries - it sounded like we had a solution in-mind.
A simple feature flag - that would do Query.select(_id) when querying Groups - building the session with less data.
Although simple and sustained by a lot of research we were still cautious by setting up lots of product metrics and log metrics to understand wether rolled customers would have negative impact - like messaging not going out, notifications being missed or even worse - entire product breakdown.
Rollout and Implementation
- We needed to ensure our libraries were at least a certain version
- Enable flag for each customer tenant id
Outcome
It took us nearly a month rolling out 90 backend services and a week enabling the flag for all customers. But the results are very expressive.
- 60% Network usage reduction. It's been weeks we don't have any alerts about Network Bandwidth
- Stable API latencies. We are now able to downsize our infrastructure back to normal levels - we are estimating to downsize REST layer resources by 1/4
- Almost zero'ed PubSub bandaid network usage. We are now
unblockedto remove thebandaidsolutions likepubsub-serviceandsessionlesscode
REST Layer p75 to p95 stability and latencies drop after 03/11 - first customers.
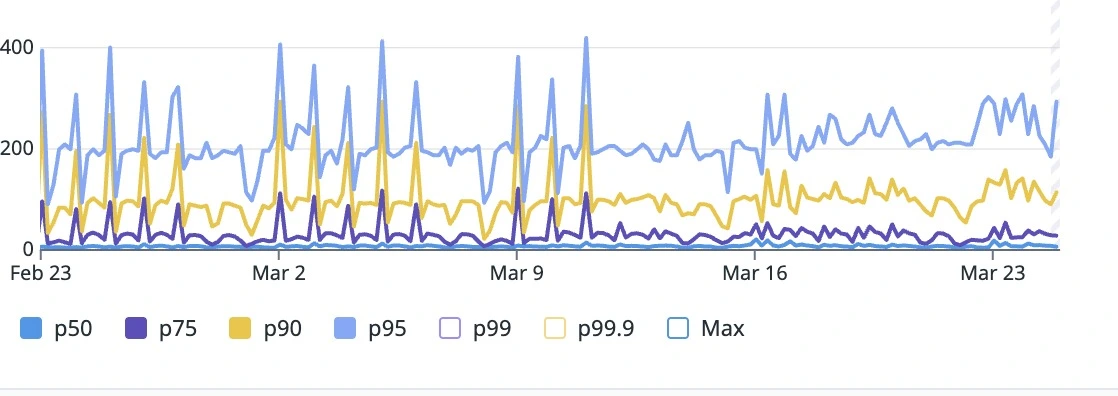
Comparing pre-rollout weeks(03/17) to post-rollout (03/17) - Check the end of the graph
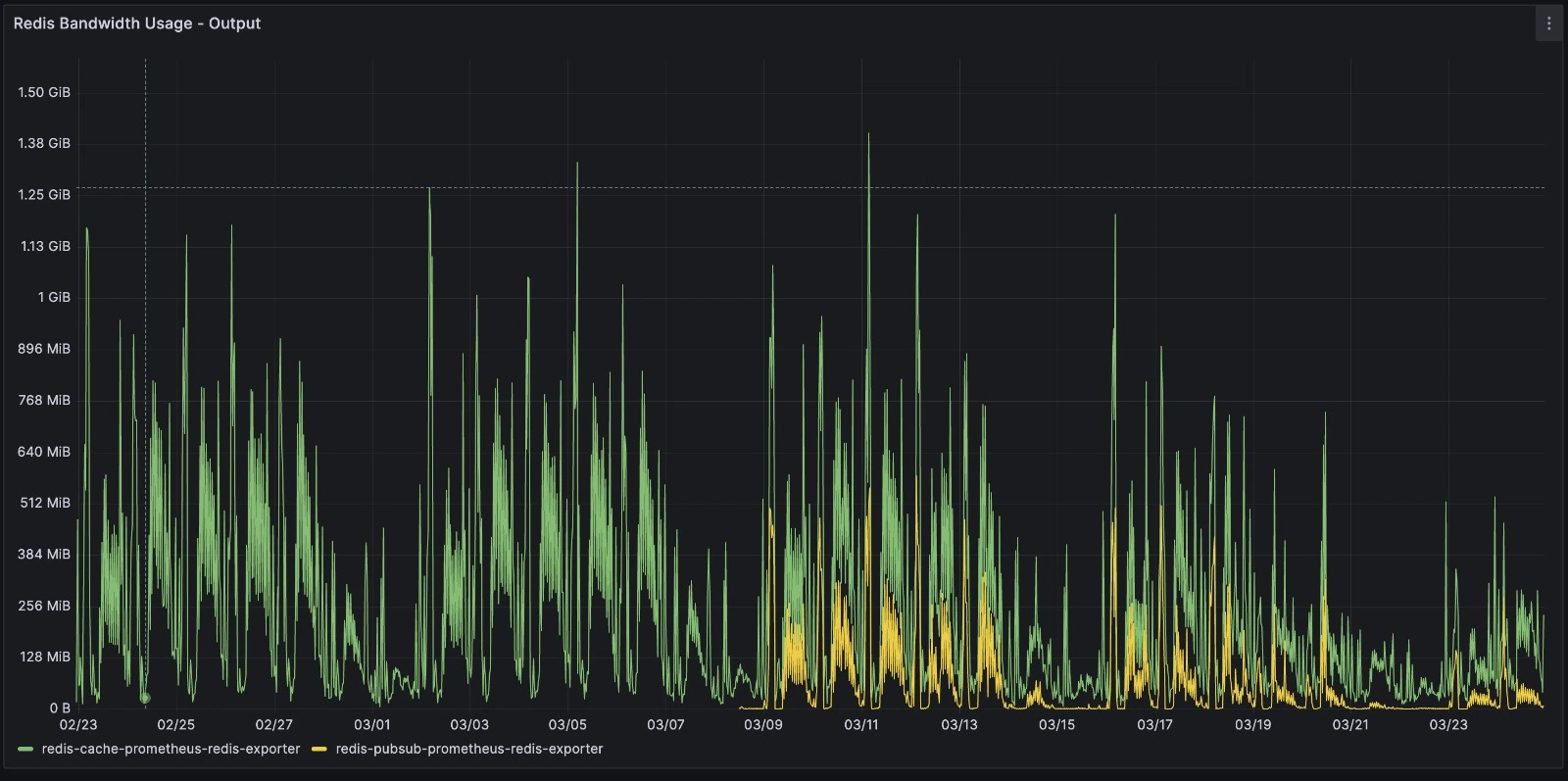
Post-Rollout Monday (Busiest day of week)
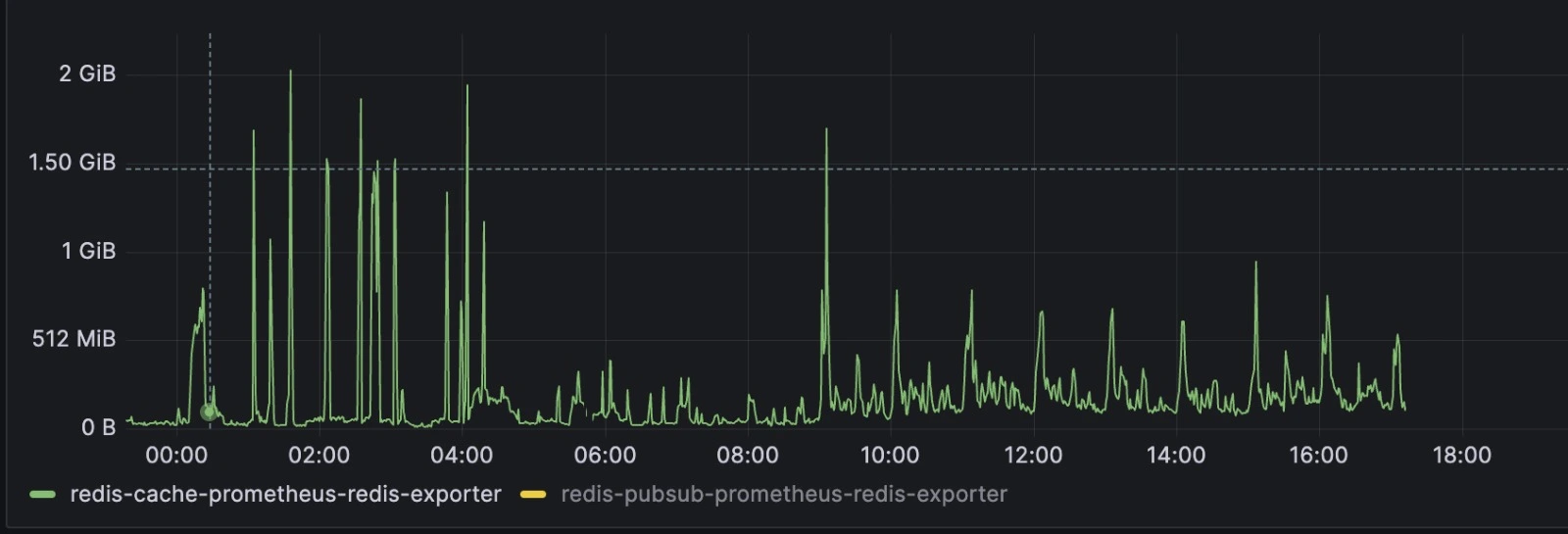 Pre-Rollout Monday (Busiest day of week)
Pre-Rollout Monday (Busiest day of week)
TakeAway Points
There's much more coming in the future - but we are happy to finally unblock the road for bigger impact optimizations.
To build good product, find market-fit, prioritize customers and market requirements is an art of business but I deeply think that there's some bounding between business and this not-so-celebrated-kind-of-stuff.
At the end of the day - delivering a reliable, stable and ever-growing platform requires revisiting past decisions - behind a healthy and stable platform is a great patient experience and efficient staff.